数据湖 全量数据存储与快速洞察的实现引擎
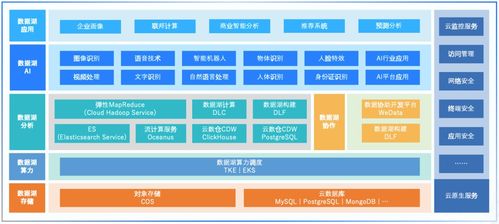
随着大数据时代的深入发展,企业面临着数据量激增、数据类型多样化和数据处理需求实时化的多重挑战。传统的数据仓库架构因其模式固定、处理速度受限、成本高昂等问题,在应对海量、多源、非结构化数据时显得力不从心。在此背景下,数据湖(Data Lake) 作为一种新兴的数据处理与存储范式应运而生,它以存储全量数据为核心,致力于快速实现数据洞察,为企业提供了一个统一、灵活、可扩展的数据处理与存储服务平台。
一、 数据湖的核心:存储全量数据
数据湖的核心设计理念在于打破传统数据存储的藩篱。与数据仓库仅存储经过清洗、转换和结构化处理的“精炼数据”不同,数据湖旨在存储来自企业内外部所有来源的原始、未经处理的“全量数据”。这些数据包括但不限于:
- 结构化数据:如关系型数据库中的交易记录、CRM系统数据。
- 半结构化数据:如JSON、XML格式的日志文件、点击流数据。
- 非结构化数据:如社交媒体文本、图片、音视频文件、传感器时序数据。
通过采用对象存储(如AWS S3、Azure Blob Storage)或分布式文件系统(如HDFS)作为底层存储,数据湖能够以极低的成本、近乎无限的扩展能力,容纳PB甚至EB级别的海量数据。这种“先存储,后处理”的模式,确保了数据的完整性和原始性,为后续灵活、多样化的分析需求保留了最大的可能性,避免了因早期数据建模而可能造成的信息丢失或分析视角受限。
二、 赋能业务:快速实现数据洞察
数据湖的价值不仅仅在于“存”,更在于“用”。其核心目标是快速实现数据洞察,驱动业务决策与创新。这主要通过以下几个层面实现:
- 敏捷分析与探索:业务分析师和数据科学家可以直接访问数据湖中的原始数据,根据具体的分析场景(如用户行为分析、市场趋势预测、设备故障预警)快速构建数据模型,进行探索性分析(EDA)。这种自助式分析模式大大缩短了从数据到洞察的周期。
- 支持高级分析与人工智能:数据湖为机器学习和人工智能应用提供了理想的“数据燃料”。全量的、多样化的原始数据是训练高质量AI模型的基石。数据科学家可以在湖中轻松获取训练所需的数据集,进行特征工程和模型迭代,从而开发出精准的推荐系统、智能风控模型或预测性维护方案。
- 统一的数据服务层:现代数据湖架构通常包含一个逻辑上的“数据服务层”。通过数据目录(Data Catalog)实现数据的可发现、可理解和可管理;通过细粒度的权限控制和数据治理策略保障数据安全与合规;通过统一的查询引擎(如Presto、Spark SQL)提供对湖中数据的标准化SQL访问接口,使得下游的BI工具、报表系统、应用程序都能便捷地消费数据,快速生成洞察。
三、 关键支柱:数据处理与存储服务
要实现上述价值,一个健壮的数据湖离不开强大的底层数据处理和存储服务作为支撑。这构成了数据湖的技术基石:
- 弹性可扩展的存储服务:提供高吞吐量、高持久性、低成本的底层存储,支持热、温、冷数据的自动分层,优化存储成本。
- 多样化计算引擎:集成批处理(如Apache Spark)、流处理(如Apache Flink、Kafka Streams)、交互式查询(如Trino)等多种计算框架,满足不同延迟和吞吐量的处理需求。数据处理管道可以灵活编排,实现从原始数据到可用数据资产(如特征、聚合表)的自动化转换。
- 统一的数据治理与安全:提供贯穿数据全生命周期的治理能力,包括元数据管理、数据血缘追踪、数据质量监控、访问审计以及基于角色的访问控制(RBAC)等,确保数据在高效利用的同时安全可控。
- 云原生与湖仓一体演进:现代数据湖越来越多地构建在云上,充分利用云服务的弹性、托管和集成优势。“湖仓一体”(Lakehouse)架构正成为趋势,它融合了数据湖的灵活性与数据仓库的管理和性能优势,在同一个数据平台上同时支持数据科学、机器学习和商业智能工作负载。
###
数据湖已从早期的概念探索,发展成为企业数字化转型的核心数据基础设施。它以存储全量数据为起点,通过整合先进的数据处理与存储服务,最终赋能于业务的快速洞察与创新。成功构建和运营一个数据湖,不仅需要强大的技术平台,更需要与之匹配的数据治理文化、组织协同和清晰的业务价值驱动。当这些要素齐备时,数据湖便能真正成为企业挖掘数据金矿、赢得未来竞争的战略性资产。
如若转载,请注明出处:http://www.jixieyouliao.com/product/25.html
更新时间:2026-04-08 01:08:13