Kafka存储原理深度解析 日志文件结构、索引机制与数据处理服务
一、Kafka存储架构概述
Kafka作为分布式流处理平台的核心组件,其存储设计以高性能、高吞吐和持久化为目标。Kafka的存储服务基于“发布-订阅”模型,采用分布式、分区的日志结构来存储消息,确保数据的顺序写入和高效读取。
二、日志文件结构
2.1 分区与分段存储
Kafka将每个主题(Topic)划分为多个分区(Partition),每个分区在物理上对应一个日志目录。日志目录下包含多个日志段文件(Log Segment),每个段文件由两部分组成:
- .log文件:存储实际的消息数据,按顺序追加写入。
- .index文件:存储消息的偏移量索引,用于快速定位消息。
- .timeindex文件:基于时间戳的索引,支持按时间范围查找消息。
2.2 日志段滚动机制
Kafka通过日志段滚动策略管理文件大小:
- 基于大小:当日志段文件达到设定阈值(如1GB)时,创建新段。
- 基于时间:定期(如7天)创建新段,便于旧数据清理。
三、索引机制详解
3.1 偏移量索引(.index文件)
偏移量索引采用稀疏索引设计,并非为每条消息建立索引,而是每隔一定字节(由log.index.interval.bytes配置)记录一条索引项。每项包含:
- 相对偏移量:相对于当前日志段基偏移量的差值。
- 物理位置:对应消息在.log文件中的起始字节位置。
查询流程:先通过二分查找在索引文件中定位最近偏移量,再在.log文件中顺序扫描找到目标消息,平衡了索引空间与查询效率。
3.2 时间戳索引(.timeindex文件)
时间戳索引记录消息时间戳与偏移量的映射关系,支持按时间范围检索消息。索引项包含:
- 时间戳:消息的时间戳。
- 相对偏移量:对应消息的偏移量。
四、数据处理与存储服务
4.1 写入流程
- 生产者发送:生产者将消息发送至指定主题分区。
- 日志追加:分区领导者将消息顺序追加到当前活跃日志段的.log文件中。
- 索引更新:根据配置的索引间隔,更新.index和.timeindex文件。
- 刷盘策略:通过
flush.messages和flush.ms参数控制刷盘频率,平衡性能与持久化。
4.2 读取流程
- 消费者请求:消费者指定主题、分区及起始偏移量。
- 索引定位:通过偏移量索引找到对应日志段及物理位置。
- 消息读取:从.log文件中读取消息数据并返回。
4.3 存储优化特性
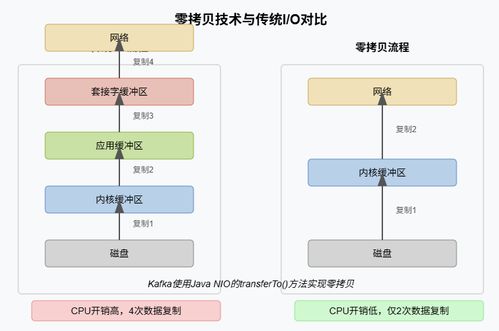
- 零拷贝技术:利用
sendfile系统调用,减少内核态与用户态数据拷贝,提升吞吐量。 - 页缓存利用:依赖操作系统页缓存缓存热点数据,避免频繁磁盘IO。
- 批量处理:支持消息批量压缩、传输,降低网络与存储开销。
五、
Kafka的存储设计通过日志分段、稀疏索引和高效IO机制,实现了高吞吐、低延迟的数据处理能力。其存储服务不仅保证了数据的持久化和顺序性,还通过灵活的索引机制支持多种查询模式,为流处理场景提供了坚实基础。
如若转载,请注明出处:http://www.jixieyouliao.com/product/7.html
更新时间:2026-04-20 14:40:49