利用Pandas与HDF5实现高效数据处理与存储服务
在数据科学和工程领域,高效的数据处理和存储是提升工作效率的关键。Pandas作为Python中最流行的数据分析库,提供了强大的数据处理能力,而HDF5(Hierarchical Data Format)作为一种高性能的二进制存储格式,能够高效地存储和管理大规模数据集。将两者结合使用,可以构建一个既高效又灵活的数据处理与存储服务。
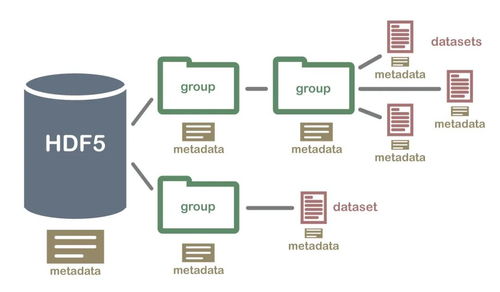
一、HDF5格式简介
HDF5是一种用于存储和组织大量数据的文件格式,它支持分层结构(类似于文件系统的目录树),允许用户以组(group)和数据集(dataset)的形式组织数据。其特点包括:
- 高性能读写:采用二进制压缩存储,读写速度快,尤其适合大规模数据。
- 跨平台兼容:支持多种编程语言(如Python、C++、Java)。
- 灵活性:可存储多维数组、元数据及复杂数据结构。
二、Pandas与HDF5集成
Pandas通过HDFStore类提供了与HDF5的无缝集成。使用pandas.HDFStore,可以轻松将DataFrame存储到HDF5文件中,并支持条件查询、数据更新等操作。以下是基本操作示例:
1. 安装依赖:确保已安装pandas和tables库(pip install pandas tables)。
2. 存储数据:
`python
import pandas as pd
# 创建示例DataFrame
df = pd.DataFrame({'A': [1, 2, 3], 'B': ['x', 'y', 'z']})
# 存储到HDF5文件
store = pd.HDFStore('data.h5')
store.put('dataset1', df, format='table', data_columns=True)
store.close()
`
3. 读取数据:
`python
store = pd.HDFStore('data.h5')
df_loaded = store.get('dataset1')
store.close()
`
三、高效数据处理与存储策略
为了最大化性能,可结合以下策略构建数据处理服务:
- 数据分块存储:对于超大规模数据,可将数据分块存储到不同HDF5节点中,避免单文件过大。Pandas支持分块读写,例如使用chunksize参数。
- 压缩存储:HDF5支持多种压缩算法(如zlib、blosc),可在存储时指定压缩级别以节省空间,例如:
`python
store.put('dataset1', df, format='table', complib='zlib', complevel=5)
`
- 条件查询优化:设置data_columns=True可为列创建索引,加速查询。例如,查询B列为'y'的数据:
`python
result = store.select('dataset1', where='B = \'y\'')
`
- 增量更新:HDF5支持追加模式,可动态添加新数据而不重写整个文件。
四、实际应用场景示例
假设我们需要为一个电商平台构建数据处理服务,存储每日用户交易数据:
- 数据采集:每日将新增交易数据(如CSV文件)加载为DataFrame。
- 预处理:使用Pandas进行数据清洗(去重、填充缺失值等)。
- 高效存储:将处理后的DataFrame追加到HDF5文件中,按日期分组存储(如
/2023/10/01/transactions)。 - 查询服务:根据日期、用户ID等条件快速检索数据,生成报表。
五、注意事项
- 版本兼容性:确保
pandas和tables库版本匹配,避免读写错误。 - 并发访问:HDF5不支持多进程同时写入,需通过锁机制或分文件存储解决并发问题。
- 内存管理:处理大数据时,使用分块读写避免内存溢出。
###
Pandas与HDF5的结合为数据处理和存储提供了一种高效、可扩展的解决方案。通过合理设计存储结构、利用压缩和索引优化,可以显著提升数据服务的性能,适用于物联网、金融分析、科学计算等多种领域。随着数据量的增长,这种方案将成为数据工程中不可或缺的一环。
如若转载,请注明出处:http://www.jixieyouliao.com/product/6.html
更新时间:2026-04-20 10:24:57