MyCat入门与配置 构建分布式数据处理与存储服务
在当今大数据和分布式系统的时代,传统的单数据库架构已难以应对海量数据和高并发访问的挑战。MyCat作为一款开源的分布式数据库中间件,应运而生,它通过将多个物理数据库节点整合成一个逻辑数据库,为应用提供了透明、高效的数据处理和存储服务。本文将引导您快速入门MyCat,并详解其核心配置方法。
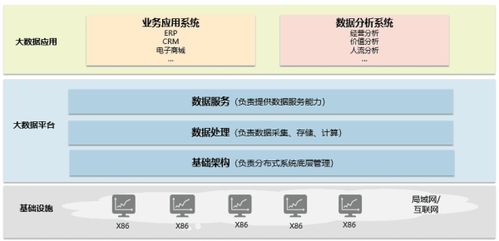
一、MyCat概述
MyCat的核心思想是“分库分表”,它位于应用与数据库之间,充当代理层。对应用程序而言,它像一个单一的数据库(如MySQL),实际的数据则根据预设的规则(如取模、范围、哈希等)分布在后端多个MySQL数据库实例中。其主要功能包括:
- 读写分离:将写操作定向到主库,读操作分摊到多个从库,提升整体吞吐量。
- 数据分片:将大表水平拆分到不同节点,解决单表数据量过大导致的性能瓶颈。
- 多租户支持:通过不同的Schema或分片规则为不同业务或客户提供数据隔离。
- 高可用与故障切换:配合后端数据库的主从复制,实现故障节点的自动转移。
二、快速入门:安装与启动
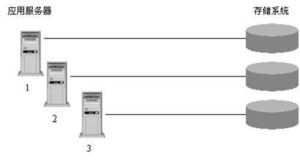
- 环境准备:确保已安装Java运行环境(JRE 1.7以上)。准备至少两个MySQL实例作为后端数据节点。
- 下载与解压:从MyCat官网或GitHub仓库下载稳定版本(如MyCat 1.6),解压至指定目录(如
/usr/local/mycat)。 - 核心配置文件:MyCat的配置主要集中在
conf目录下:
server.xml:定义MyCat服务器参数、系统用户及权限。
schema.xml:定义逻辑库、逻辑表、数据节点以及它们与物理数据库的映射关系。
rule.xml:定义数据分片规则。
- 启动与连接:进入
bin目录,执行./mycat start。使用MySQL客户端通过mysql -h127.0.0.1 -P8066 -uroot -p123456连接MyCat(默认管理端口9066,服务端口8066)。
三、核心配置详解
1. server.xml 配置:
在此文件中,您需要配置MyCat的系统参数和用户。关键元素包括:
`xml
`
这里定义了一个用户及其权限。
2. schema.xml 配置:
这是配置的核心,定义了数据的逻辑组织和物理分布。
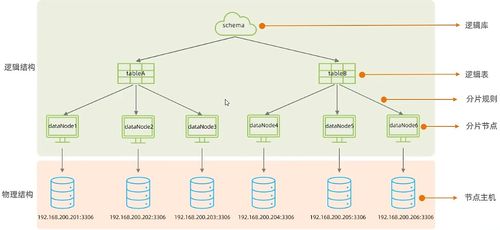
- 逻辑库与逻辑表:
<schema>标签定义对应用暴露的逻辑数据库,其内的<table>标签定义逻辑表。
- 数据节点:
<dataNode>标签将逻辑表的数据映射到具体的物理数据库实例上。一个数据节点对应一个物理数据库(或库中的特定分片)。
- 数据源:<dataHost> 标签定义实际的MySQL实例地址、端口、读写分离配置及心跳检测。
示例:
`xml
`
此配置将 orders 表的数据分片到两个数据节点(dn1, dn2)上,并配置了主从读写分离。
3. rule.xml 配置:
此文件定义了分片规则的具体算法。例如,上述 mod-long 规则可能定义为对id字段进行2取模,将数据均匀分布到两个节点。您可以在此配置分区字段、分区算法和分区数量。
四、数据处理服务实践
配置完成后,应用程序只需像连接单一MySQL一样连接MyCat。当执行SQL时,MyCat会完成以下关键处理:
- SQL解析与路由:解析SQL语句,根据分片规则计算出数据所在的一个或多个物理节点,将请求转发过去。
- 结果合并:对于跨多个节点的查询(如不带分片键的查询或聚合操作),MyCat将各节点返回的结果在内存中进行合并、排序等处理后返回给客户端。
- 事务管理:支持分布式事务(XA事务),但在跨节点更新时需谨慎处理,通常建议业务设计时尽量让事务落在单一数据节点内。
五、配置优化与注意事项
- 分片键选择:选择离散度高的字段(如用户ID)作为分片键,避免数据倾斜。
- 避免跨分片关联:Join操作跨多个数据节点性能极差,应通过数据冗余、全局表或业务设计规避。
- 全局序列号:为分片表提供全局唯一的ID生成方案,如使用数据库序列、本地时间戳算法或ZooKeeper。
- 监控与日志:充分利用MyCat提供的管理命令(通过9066端口连接)和日志文件(logs/目录下)进行监控和问题排查。
MyCat通过巧妙的中间件设计,极大地简化了分布式数据库系统的构建与运维。掌握其核心配置是发挥其威力的关键。从定义逻辑结构到映射物理节点,再到选择分片规则,每一步都需结合具体的业务场景和数据特性。随着对MyCat的深入理解,您可以构建出既能水平扩展,又能保持应用透明访问的健壮数据处理与存储服务层。
如若转载,请注明出处:http://www.jixieyouliao.com/product/4.html
更新时间:2026-04-20 12:55:19