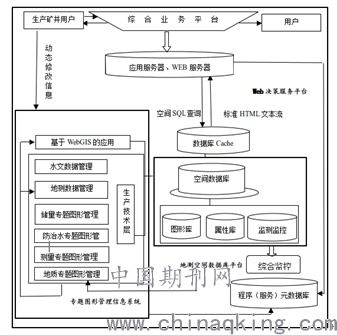
未来物联网 数据处理与存储,人工智能无法逾越的技术基石

当我们畅想物联网与人工智能交织的未来时,无人驾驶汽车、智能家居、工业4.0等场景令人心驰神往。人工智能算法如同大脑,赋予万物“思考”与“决策”的能力。一个常被忽略却至关重要的现实是:无论人工智能如何进化,其运行与成长都严重依赖于一个更为基础的技术领域——数据处理与存储服务。这并非AI的附属品,而是其无法迈过的技术基石与先决条件。
1. 数据洪流:物联网的基石与AI的“食粮”
物联网的本质是“万物互联”,其产生的数据量是前所未有的指数级增长。数以百亿计的传感器、设备每时每刻都在采集环境、位置、状态、图像、声音等海量、多源、异构的实时数据。对于人工智能而言,无论是机器学习模型的训练,还是深度学习网络的推理,高质量、大规模的数据集是其“学习”和“变聪明”的唯一食粮。没有持续、可靠、高效的数据采集与汇聚,AI将成为无源之水、无本之木。因此,构建能够应对数据洪流的采集、清洗与传输网络,是比设计精妙算法更为基础的挑战。
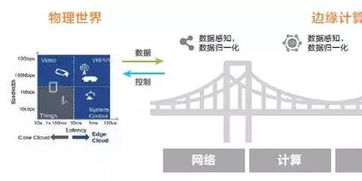
2. 实时处理与边缘计算:决定智能的“即时性”
物联网场景下的许多应用,如自动驾驶的紧急避障、工业机器的预测性维护、医疗设备的实时监护,都对延迟有近乎苛刻的要求。将海量数据全部传输至云端由中心化AI处理,往往无法满足实时响应的需求。这就催生了对边缘计算的深度依赖。在数据产生的源头或近端进行预处理、过滤和初步分析,只将关键信息或聚合结果上传,这极大减轻了网络带宽压力,并实现了低延迟智能决策。边缘计算架构中高效、低功耗的数据处理单元(如专用AI芯片)及其与云端的协同,是确保AI在物联网中“即时生效”的关键技术,其重要性不亚于AI模型本身。
3. 安全、可靠与海量的存储:智能的“记忆”与“保障”
物联网数据不仅体量巨大,且价值密度不均,需要长期乃至永久保存以供模型持续优化、合规审计和历史追溯。这对存储系统提出了极高要求:
- 海量可扩展性:需要EB甚至ZB级别的存储容量,并能随数据增长无缝扩展。
- 高可靠与持久性:数据是核心资产,必须通过分布式存储、多副本、纠删码等技术确保数据不丢失。
- 安全性:涉及个人隐私、商业机密和基础设施运行的数据,必须通过加密、访问控制、安全协议等手段进行全方位保护,防止数据泄露与篡改。数据安全是物联网AI系统获得信任的生命线。
- 存取效率:支持对热数据、温数据、冷数据的分层存储与智能化管理,以平衡成本与访问速度。
没有强大、智能、安全的存储后端,AI模型训练所需的历史数据无法积累,系统的连续性和可靠性也无从谈起。
4. 数据治理与隐私计算:合规与伦理的“护栏”
随着数据法规(如GDPR、个保法)日益严格,物联网产生的大量个人和敏感数据的使用面临严格限制。如何在合法合规的前提下,让数据“可用不可见”,赋能AI发展?这需要先进的数据治理框架和隐私计算技术(如联邦学习、安全多方计算、差分隐私)。这些技术使得AI模型可以在不直接交换原始数据的情况下进行协同训练,在保护数据主权与隐私的同时释放数据价值。这不仅是技术问题,更是关乎AI能否在物联网领域大规模、合规落地的社会性、规范性课题。
结论
总而言之,在未来物联网与人工智能深度融合的宏伟图景中,数据处理(包括采集、传输、实时边缘处理)与存储服务(包括海量存储、安全、治理)构成了整个智能系统的“循环系统”与“记忆中枢”。它们是承载AI算法、滋养AI进化、保障AI可靠运行的基础设施。无论人工智能算法如何精进,迈向通用人工智能(AGI)的道路多么漫长,其每一步都深深踏在数据处理与存储技术构筑的基石之上。忽略或轻视这一领域,任何关于物联网智能化的设想都将成为空中楼阁。因此,持续投资并突破数据工程与存储技术的瓶颈,与推进AI算法创新同等重要,甚至更为根本。
如若转载,请注明出处:http://www.jixieyouliao.com/product/10.html
更新时间:2026-03-23 03:41:46